
One of the pillars of the recent success (almost viral) of Deep Networks, a subspecies of the bigger class called Neural Networks, is that their execution and training methods are highly conducive to parallelism. The term GPGPU is often use to refer to the backbone of the revolution: General-Purpose computation on Graphics Processing Units. GPUs, chips whose main technological push comes from huge revenues from the gaming market, and more recently are finding their ways into mobile devices, are in reality high-performance many-core processors that can be used to accelerate a wide range of applications, going from physics, to chemistry, to computer vision, to neuroscience. And, of course, Deep Networks.
How Deep in the past go Deep Networks and GPUs? And how Deep in the past go the theories that are the backbones of the recent surge in popularity of these algorithms? Jürgen Schmidhuber (Pronounce: You_again Shmidhoobuh), a professor at IDSIA in Lugano, Switzerland, provides a great historical survey which summarizes how the Deep Network field origins go back to the previous millennium. He is right: Deep Networks are the results of the combination, permutation, mutation, and refinements of algorithms that have been researched and fielded in the past few decades. But let's get to GPUs....
 It was a cold and rainy winter in 2004, when Anatoli Gorchetchnikov, Heather Ames and myself got really interested in general purpose computing on graphic processing cards. At the time, there was no CUDA or OpenGL available: programming GPUs was really tough. I call that "BC" (Before Cuda) times...But we tried, with some very good results, to port some of the models we used on GPUs. It was so good that we wrote a patent around that work, and we created a company, Neurala, to contain it. Years later, the company has raised money, entered TechStars, and launching products, but this is yet another story!
It was a cold and rainy winter in 2004, when Anatoli Gorchetchnikov, Heather Ames and myself got really interested in general purpose computing on graphic processing cards. At the time, there was no CUDA or OpenGL available: programming GPUs was really tough. I call that "BC" (Before Cuda) times...But we tried, with some very good results, to port some of the models we used on GPUs. It was so good that we wrote a patent around that work, and we created a company, Neurala, to contain it. Years later, the company has raised money, entered TechStars, and launching products, but this is yet another story!
First of all, a disclaimer: the GeForceR 6800 used at the time is today a museum piece…nevertheless, many of the arguments that follow are still relevant.
As you may have heard, Deep Networks or Artificial Neural Networks (ANNs) are highly parallel, computationally intensive mathematical models that capture the dynamics and adaptability of biological neurons. Neurons are cells that make up most of the nervous system. An adult human brain weights approximately 1.3 Kg and includes 100 billion neurons. The neuron’s axon then communicates signals to other neurons (approximately, each neuron is connected to other 10,000 neurons).
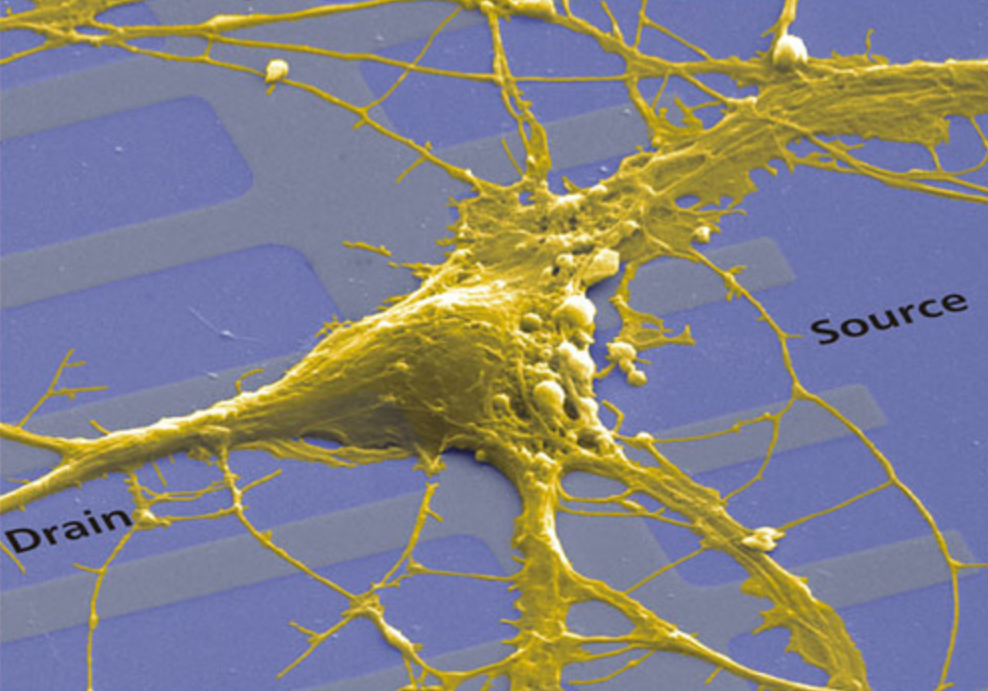 The artificial counterparts of biological neurons are dynamical systems requiring numerical integration to calculate their variables at every moment of time as a function of previous values of one or more of these variables. In certain classes of ANNs, neurons are described in terms of complex system of differential equations, and a significant degree of recurrency can characterize their connectivity matrix. Graphic processing units (GPUs), originally designed for computer gaming and 3D graphic processing, have been used in general-purpose, computationally intensive models in application domains ranging from physical modeling, image processing, and computational intelligence. Biologically realistic neural networks are used to model brain areas responsible for perceptual, cognitive, and memory functions. You can read more details in this post
The artificial counterparts of biological neurons are dynamical systems requiring numerical integration to calculate their variables at every moment of time as a function of previous values of one or more of these variables. In certain classes of ANNs, neurons are described in terms of complex system of differential equations, and a significant degree of recurrency can characterize their connectivity matrix. Graphic processing units (GPUs), originally designed for computer gaming and 3D graphic processing, have been used in general-purpose, computationally intensive models in application domains ranging from physical modeling, image processing, and computational intelligence. Biologically realistic neural networks are used to model brain areas responsible for perceptual, cognitive, and memory functions. You can read more details in this post
Despite the roots of the theory and GPU computation go really deep in the past, the introduction of constantly smaller/more power efficient GPUs is changing the range of applicability of these technology. Recently, the main player in GPU, nVidia, unveiled in this recent post the release of the NVIDIA Jetson TX1 Developer Kit, a mobile GPU which, in my opinion, will be a game-changer in enabling more portable and ubiquitous artificial intelligence applications, from mobile robots to drones.
Smaller GPU, bigger Drones/Robotic markets. As simple as that.

