
Yes, building AI is hard! Every step from data annotation, training and deployment comes with its own set of challenges. This blog post will try to deal with the first two of those:
- Data Annotation
- Training
Over the past few years at Neurala, we have been developing highly efficient AI systems deployed in millions of consumer devices as of today! And in this process, we developed a lot of tools to simplify our workflow. We have finally decided to bridge the AI skills gap by making some of our tools public. One of the tools, Brain Builder deals with the first of the aforementioned issues: Data Annotation.
Brain Builder is an AI-assisted annotation tool that fits seamlessly into commonly used frameworks like TensorFlow and Caffe. This post will walk you through the steps you’d need to incorporate Brain Builder into your AI workflow. We will build a semantic segmentation network using the data tagged by Brain Builder and model written using TensorFlow and Keras.
Semantic segmentation is one of the commonly encountered applications of computer vision. It is the task of labeling every pixel of an image with a class. It is used extensively for image analysis and enables applications like portrait mode on smartphones. The following tutorial will describe how you can create a semantic segmentation model to segment people using your own data and train it over multiple GPUs, using Brain Builder and TensorFlow.
Data Annotation using Brain Builder
Data annotation is the most crucial step in building an AI system since this is what your model learns from. And a deep learning model is only as good as the data it’s fed! Brain Builder helps you in curating a quality dataset and has AI-assisted tools to speed up the data curation step.
One of the most important features of Brain Builder is automated video tagging. AI-assisted video tagging lets you collect a lot of data in a small amount of time by extracting and tagging frames from videos recorded at very high frame rates.
The following video shows the process of tagging people in videos using brain builder:
As you can see, just by tagging the first frame in the video, you’ve accumulated close to 500 tagged frames of people in just a few minutes! Once you’re done tagging and exporting your data, you’ll get a zipped file from Brain Builder which has the following folder structure:
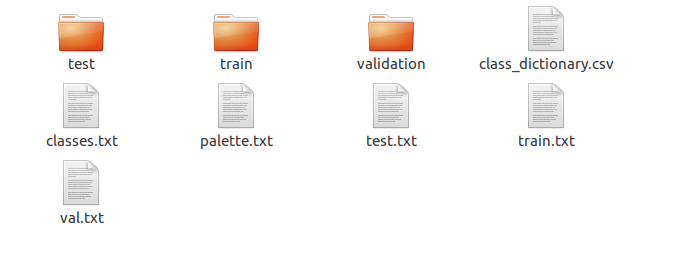
The folder contains everything you will need in order for TensorFlow to be able to read and process your dataset. All the ground truth images are class index-labeled pngs, where every pixel in the image corresponds to a class index. The files class_dictionary.csv, classes.txt and palette.txt provide you details about the mapping of class index to their subsequent R, G, B values that you can later use for visualizing your results.
We will now write a popular architecture for semantic segmentation called UNet using TensorFlow and Keras. Using Estimators and the TensorFlow Dataset API, we’d enable training over multiple GPUs to reduce the training times massively!
(Please note that we’ve modified the UNet slightly in our implementation to make this a quicker experiment!)
Multi-GPU training using TensorFlow Estimators and Dataset API
End-to-end integration of Keras with TensorFlow has made it easy to enable multi-GPU training of Keras models using TensorFlow Estimators and Dataset API.
TensorFlow Estimators
The Estimator class represents a model, as well as how this model should be trained and evaluated. Some of the key advantages of using Estimators are:
- Estimator based models can be run across multiple GPUs without changing the model code;
- Estimators simplify sharing the implementation of models across developers;
- Estimators build the graph for you and eliminate the need of an explicit (and rather painful) session.
The following piece of code creates a Keras model, compiles it and converts it to an TensorFlow Estimator:

If you’re familiar with Keras, the only new things you’d notice are the last three lines of code. The strategy we use for multi-GPU training is called MirroredStrategy . In this strategy, each GPU has a copy of the graph and gets a subset of the data on which it computes the local gradients. Once the local gradients are computed, each GPU then waits for other GPUs to finish in a synchronous manner. When all the gradients have arrived each GPU averages them and updates its parameter and the next step begins. You can learn more about the Distributed TensorFlow training on this link.
Now that the strategy has been defined, we create a RunConfig object using that strategy and use it to call the model_to_estimator function which converts the Keras model into an Estimator object.
With the estimator ready, we can simply train and evaluate it using these two lines of code:

The important thing to note in these two calls is the dataset.imgs_input_fn function. This function feeds the model the data using the TensorFlow Dataset API.
TensorFlow Dataset API
Dataset is a highly efficient API for data input that ties nicely with the Estimators and tf.Keras. The core of the new input pipeline is the Dataset(and maybe the Iterator). A Datasetis a collection of elements, each with the same structure, where one element can be one or more tensors. The different tensors inside an element are called components. Each component has a certain data type and shape, but different components inside one element can have different data types and shapes.
The following code snippet shows how to create a dataset object that can be fed to the Estimators:

The important function to take a note of is the map() function that lets you read the data and process it any way you want (resize, one-hot code, etc). repeat() lets you specify how many times you want to iterate over this dataset. batch() automatically batches the data based on the batch size provided by the user and prefetch() prefetches the next batch while the current batch is being processed.
Training Results and Speed Comparison
We train our segmentation model for 100 epochs over two NVIDIA GTX1080 GPUs. The model attains about 91% pixel accuracy with just about 4 hours of training. Here are some comparisons from our tests:
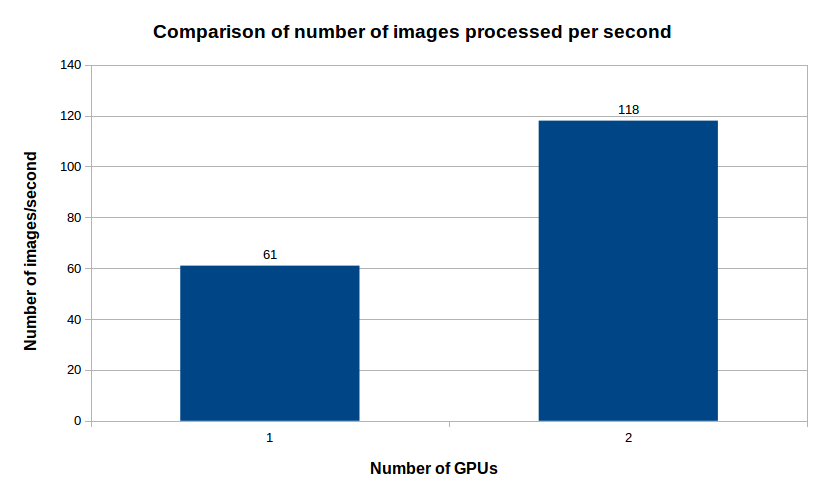
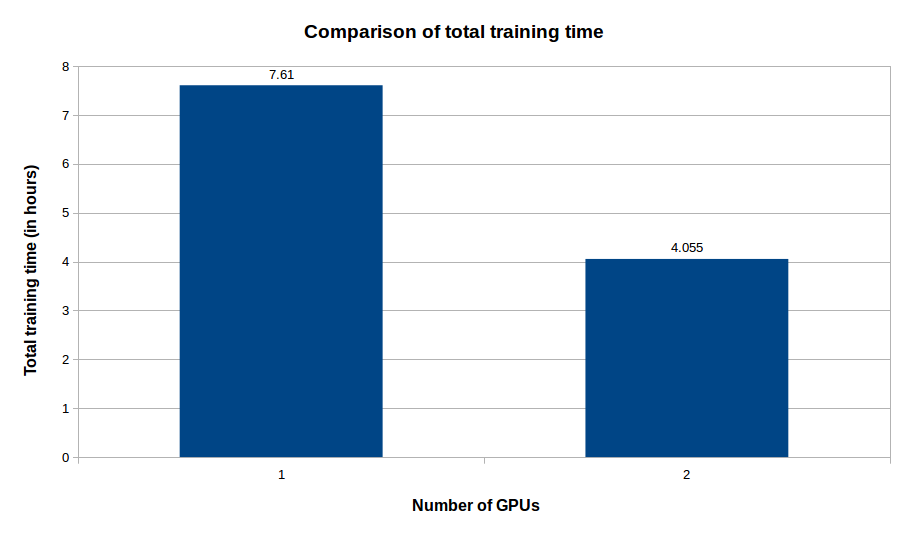
As you can see, using two GPUs instead of one gives us a speedup of almost 2x to attain the same level of accuracy.
We hope this tutorial helped you understand how you can integrate Brain Builder into your AI workflow to build highly efficient data preparation and training pipelines. We welcome the feedback from the community in order to be able to improve Brain Builder further!
You can sign up for Brain Builder Beta here. Leave a comment below with feedback, feature requests or any further questions you might have related to the tutorial and/or Brain Builder.
You can find the code for this tutorial on this link.
